빅데이터 관련 기술
빅데이터는 수집, 정제, 적재, 분석의 단계를 거치면서 다양한 기술을 이용하여 처리 된다.
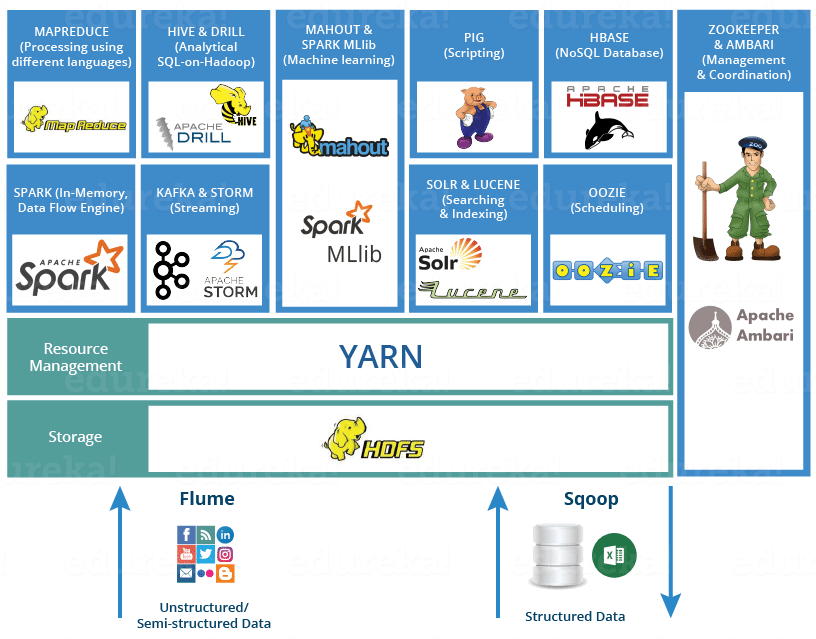
Hadoop
- HDFS, Mapreduce로 구성된 빅데이터 처리 기술
- 자바로 구현된 대규모 분산처리를 위한 오픈소스 프레임워크
HBase
- HDFS 기반의 칼럼 기반 데이터베이스
- HDFS 위에서 동작하는 NoSQL 데이터 베이스
- 실시간 조회 및 업데이트 가능
- https://hbase.apache.org/
hbase(main):003:0> describe 'test' Table test is ENABLED test COLUMN FAMILIES DESCRIPTION {NAME => 'cf', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'f alse', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'} 1 row(s) Took 0.9998 seconds
Pig
- 복잡한 맵리듀스 프로그래밍을 대체할 Pig Latin이라는 자체 언어 제공
- 맵리듀스 API를 크게 단순화함
- SQL과 유사한 형태
- http://pig.apache.org/
A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, gpa:float); B = FOREACH A GENERATE name; DUMP B;</code></pre>
Hive
- HDFS위에서 동작하는 데이터웨어하우징용 솔루션
- SQL과 매우 유사한 HiveQL 쿼리 제공
- 내부적으로맵리듀스 잡으로 변환되어 실행
- 자바를 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와줌
- 짧은 임시쿼리보다는 일괄적인 MapReduce처리에 이상적임
- https://hive.apache.org/
hive> SELECT DISTINCT col1, col2 FROM t1; 1 3 1 4 2 5
Mahout
- 하둡 기반의 기계학습(Machine Learning) 프레임워크
- Java/Scala 로 필요한 프로그램을 구현 처리
- https://mahout.apache.org/https://mahout.apache.org/)
Hcatalog
- 하둡으로 생성한 데이터를 위한 테이블 및 스토리지 관리서비스
- Hcatalog의 이용으로 Hive에서 생성한 테이블이나 데이터 모델을 Pig나 맵리듀스에서 손쉽게 이용할 수 있음
- https://cwiki.apache.org/confluence/display/Hive/HCatalog+UsingHCat
Avro
- RPC(Remote Procedure Call)과 데이터 직렬화를 지원
- JSON을 이용해 데이터 형식과 프로토콜을 정의
- 작고 빠른 바이너리 포맷으로 데이터를 직렬화
- https://avro.apache.org/
Flume
- 분산된 서버에서 데이터를 수집하는 도구
- 병렬적으로 분산처리하면서 수집 가능
- https://flume.apache.org/
Sqoop
- 대용량 데이터 전송 솔루션
- HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송할 수 있는 방법 제공
- 상용RDBMS도 지원하고, MySQL, PostgreSQL 오픈소스 RDBMS도 지원함
- http://sqoop.apache.org/
Zookeeper
분산 환경에서 서버 간의 상호 조정이 필요한 서비스를 제공
- Active 서버에 문제가 발생시 대기중인 서버로 변경하여 고가용성 제공
- 서버간 서비스의 로드 밸런싱, 처리 결과에 대한 동기화로 데이터 안정성 보장
- http://zookeeper.apache.org/
Oozie
- 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템
- 자바 웹 애플리케이션 서버로 UI 제공
- 맵리듀스 작업이나 hive, pig 작업 같은 특화된 액션으로 구성된 XML 포맷의 워크플로우 제어
- https://oozie.apache.org/
드루이드
- 고성능 칼럼 기반의 데이터 저장소
- 대화형 쿼리 지원
- 실시간 스트림 처리
- 수평적 확장(scalable), 범용 하드웨어 가능
- http://druid.io/
반응형
'빅데이터' 카테고리의 다른 글
| [빅데이터] 아파치 피닉스(Apache Phoenix) (0) | 2019.08.01 |
|---|---|
| [빅데이터] ORC와 Parquet 파일 저장 형식 (0) | 2019.02.19 |
| [빅데이터] 실무자를 위한 빅데이터 #1 빅데이터 개요 (0) | 2018.05.03 |
| [빅데이터] 하둡 에코 시스템 (0) | 2018.02.13 |
| [개념] 빅데이터 (0) | 2017.12.20 |