카프카란?
- Apache Kafka는 링크드인에서 개발한 분산 스트리밍 플랫폼(distributed streaming platform)
- 2019.09 현재 2.3.0 버전이 가장 최신
- 생산자는 데이터를 생성
- 카프카 서버(브로커)는 데이터를 파티션 단위로 저장
- 데이터를 저장할 때 디스크를 이용하여, 장애가 발생하여도 데이터 유실이 없음
- 하드디스크의 순차적 읽기 기능을 이용하여 속도를 유지
- 사용자는 브로커에 데이터를 요청하여 데이터를 가져감
유스케이스
- 메시징(Messaging)
- 생산자(Producer)와 사용자(Consumer) 사이의 메시지 전달
- 웹사이트 동작 체크(Website Activity Tracking)
- 웹사이트의 운영 메시지를 전달하여 동작 체크 가능
- 메트릭(Metrics)
- 서버, 애플리케이션의 운영데이터를 수집하여 모니터링 가능
- 로그 수집(Log Aggregation)
- 여러서버의 로그를 모아서 수집 가능
- 스트림 처리(Stream Processing)
- 스트리밍 데이터를 받아서 전달 가능
- 이벤트 소싱(Event Sourcing)
- 시간 순서로 상태의 변경을 기록하여 상태 변경을 기록하는 용도로 사용
- 커밋 로그(Commit Log)
- 분산 시스템의 외부 커밋 로그처럼 동작하여 노드간 데이터 복제를 돕고 실패한 노드가 데이터를 복원할 수 있도록 동작
4API
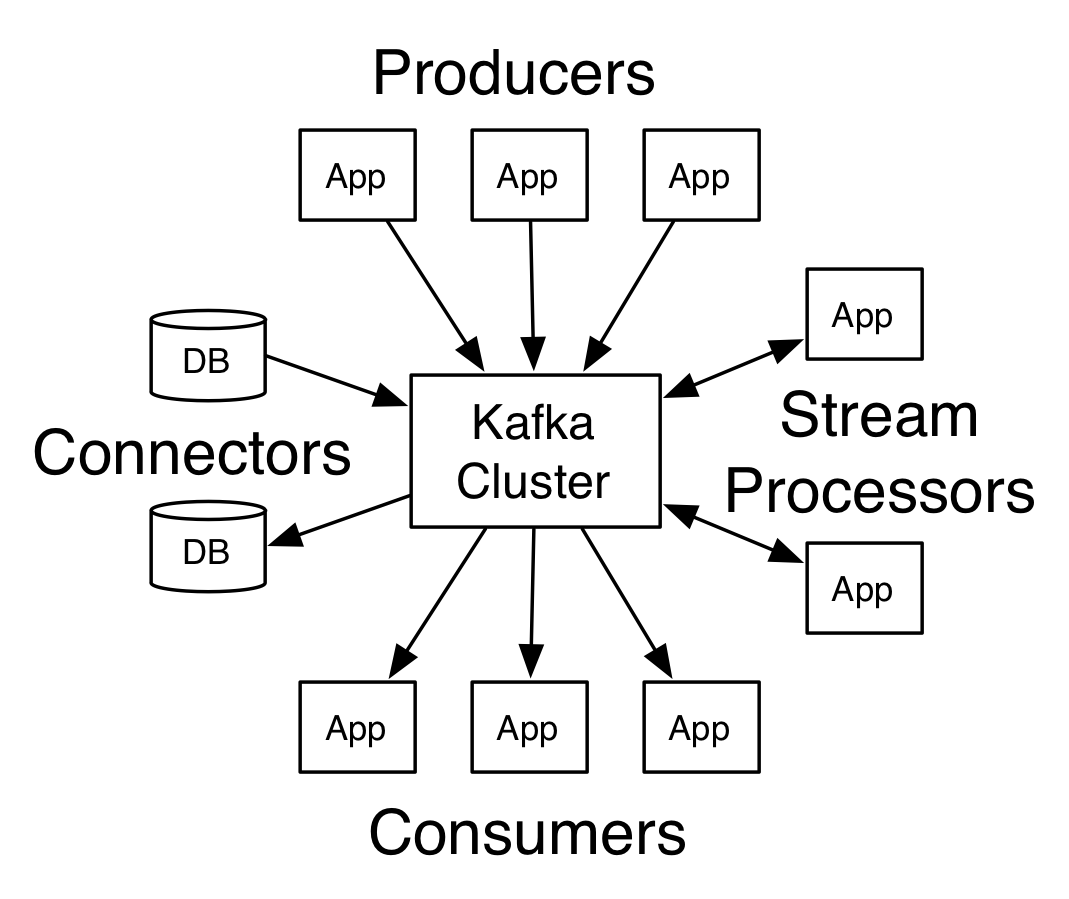
- Producer API
- 애플리케이션은 이 API를 이용해서 하나 이상의 카프카 토픽에 스트림 레코드를 발행(publish)
- Consumer API
- 애플리케이션은 이 API를 이용해서 하나 이상의 카프카 토픽으로 부터 스트림 레코드를 구독(subscribe)
- Streams API
- 애플리케이션이 하나 이상의 토픽에서 입력 스트림을 읽고 변환해서 하나 이상의 출력 토픽으로 스트림을 전달(input streams to output streams)
- Connector API
- Connector를 이용해서 재 사용 가능한 Producer 혹은 Consumers를 카프카 토픽에 연결
- 예를 들어 관계형 데이터베이스 컨넥터는 테이블의 모든 변화를 캡쳐 함
토픽과 파티션
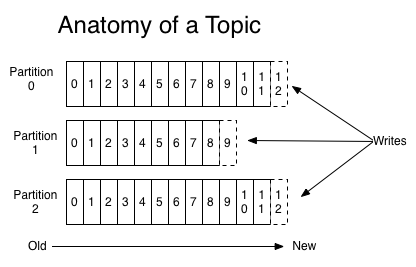
- 토픽은 스트림을 발행하는 단위
- 스트림의 발행과 구독은 토픽단위로 처리
- 토픽은 파티션 단위로 저장
- 토픽을 생성할 때 설정한
replica단위로 파티션이 생성되어 분산 저장
- 토픽을 생성할 때 설정한
설치 및 실행
- 주키퍼 실행
- 카프카는 주키퍼와 함께 동작하기 때문에 꼭 실행해야 함
- 카프카 서버 실행
- 토픽 생성
- 프로듀서 실행
- 컨슈머 실행
# 카프카 다운로드
$ wget http://apache.mirror.cdnetworks.com/kafka/2.3.0/kafka_2.12-2.3.0.tgz
# 압축 해제
$ tar -xf kafka_2.12-2.3.0.tgz
# 1. 주키퍼 실행
$ bin/zookeeper-server-start.sh config/zookeeper.properties
# 2. kafka 서버 실행: 브로커: Broker
$ bin/kafka-server-start.sh config/server.properties
# 3. Topic 생성
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
# 3-1. Topic 확인
$ bin/kafka-topics.sh --list --bootstrap-server localhost:9092
test
# 4. 메시지 전송: 프로듀서: Producer
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
>abcd
>efgh
# 5. 메시지 확인: 컨슈머: Consumer
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
abcd
efgh참고
- https://kafka.apache.org/
- https://devtimes.com/bigdata/2019/01/18/what-is-kafka/
- https://epicdevs.com/17
- https://engkimbs.tistory.com/691
- https://www.joinc.co.kr/w/man/12/Kafka/about
- http://www.chidoo.me/index.php/2016/11/06/building-a-messaging-system-with-kafka/
- https://medium.com/@umanking/%EC%B9%B4%ED%94%84%EC%B9%B4%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0-%ED%95%98%EA%B8%B0%EC%A0%84%EC%97%90-%EB%A8%BC%EC%A0%80-data%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0%ED%95%B4%EB%B3%B4%EC%9E%90-d2e3ca2f3c2
Kafka를 이용한 메시징 시스템 구성하기
최근의 개발 경향은 확실히 마이크로서비스를 지향한다. 가능하면 작은 어플리케이션을 만든다. 그리고 이 어플리케이션들의 소위 콜라보(Collaboration)로 하나의 시스템이 만들어진다. 혹은 만들어지게 구성을 한다. 이와 같은 마이크로서비스 모델이 주는 이점은 나도 몇 번 이야기를 했고, 많은 사람들이 장점에 대해서 구구절절하게 이야기하기 때…
www.chidoo.me
반응형
'빅데이터 > kafka' 카테고리의 다른 글
| [kafka] golang kafka 클라이언트 SSL 설정 (0) | 2023.03.13 |
|---|---|
| [Kafka] 카프카 운영시 주의 사항 스크랩 (0) | 2020.06.03 |