하이브의 세가지 조인 방식에 대해서 알아보겠습니다.
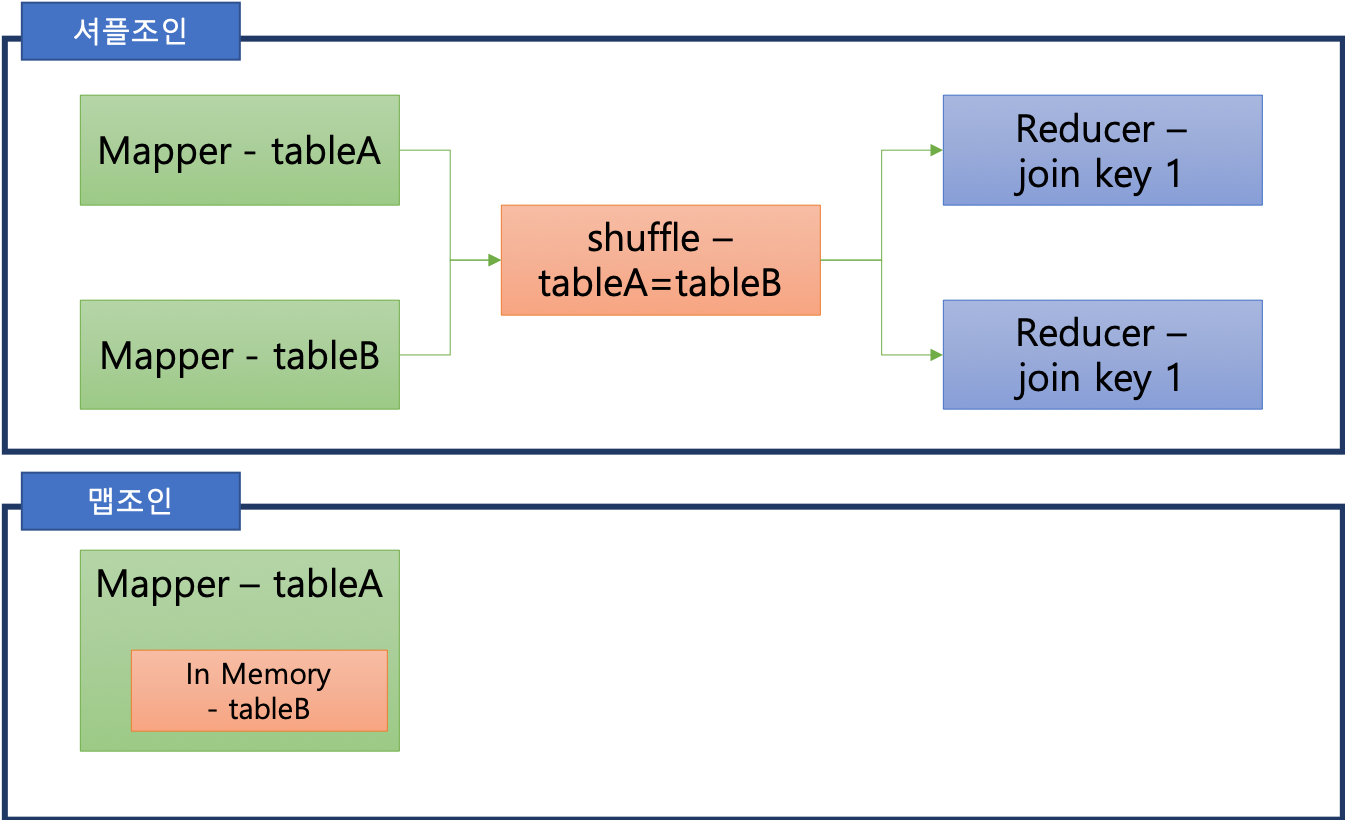
셔플조인
- 매퍼에서 각 테이블을 읽고 셔플 단계에서 조인되는 키를 기준으로 파티션닝후 셔플을 진행하여 각 리듀서에서 조인을 수행
- 어떤형태의 데이터 크기와 구성에도 사용 가능
- 가장 자원을 많이 사용하고 느린 조인 방식
맵조인 (브로드캐스트 조인, 맵사이드 조인)
- 작은 사이즈의 테이블이 메모리에 올라가고, 각 매퍼에서 조인을 수행후 결과를 반환하는 방식
- 가장 큰 테이블에서 가장 빠른 단일 스캔
- 작은 테이블은 메모리에 들어갈 정도로 작아야 함
-- 맵조인 사용여부 설정, 3개 이상의 테이블을 조인할 때 맵조인 사용여부 설정하는 옵션
hive> set hive.auto.convert.join=true;
hive> set hive.auto.convert.join.noconditionaltask=true;
hive> set hive.auto.convert.join.noconditionaltask.size=10000000;
-- 맵조인에 사용되는 테이블의 사이즈 설정 30MB 이하면 맵조인
hive> set hive.mapjoin.smalltable.filesize=30000000;
-- 맵조인의 기준 테이블 설정 힌트
Select /*+ MAPJOIN(b) */ a.key, a.value
from a join b on a.key = b.key
정렬-병합-버킷 조인
- 테이블이 버켓팅 되어 있을 때 사용할 수 있는 조인
- 매퍼는 각 키가 인접한 특성을 이용해 효과적인 조인을 수행
- 어떤 크기의 테이블에서도 굉장히 빠름
https://weidongzhou.wordpress.com/2017/06/07/join-type-in-hive-map-join/https://grisha.org/blog/2013/04/19/mapjoin-a-simple-way-to-speed-up-your-hive-queries/
https://weidongzhou.wordpress.com/2017/06/06/join-type-in-hive-common-join/
https://weidongzhou.wordpress.com/2017/06/07/join-type-in-hive-map-join/
반응형
'빅데이터 > hive' 카테고리의 다른 글
| [hive] UDF에서 발생하는 argument type mismatch 오류 수정 (0) | 2020.01.14 |
|---|---|
| [hive] 벡터화(vectorized) 처리 (0) | 2020.01.07 |
| [hive] Blobstore 기능으로 처리 속도 증가 (0) | 2019.12.19 |
| [hive] MSCK is missing partition columns under location. 오류 해결 방법 (0) | 2019.12.04 |
| [hive] Error in getting fields from serde.Invalid Field null 오류 수정 방법 (0) | 2019.12.04 |