
 [빅데이터] Apache Livy
[빅데이터] Apache Livy
Apache livy는 REST Aapi를 이용해서 스파크 작업을 요청할 수 있는 서비스입니다. REST Api와 자바, 스칼라 라이브러리를 이용해서 작업을 요청할 수 있습니다. 다음의 특징을 가집니다. 멀티 클라이언트에서 여러 개의 스파크 작업을 요청할 수 있음 작업 간 RDD와 데이터 프레임 공유가 가능 여러 개의 스파크 컨텍스트를 관리할 수 있고, 스파크 컨텍스트는 얀이나 메조스 같은 클러스터에서 실행(Livy 서버에서 실행되지 않음) 스파크 작업은 JAR, 자바/스칼라 API, 코드 조각을 통해 요청 보안 통신을 이용해 안정성 제공 REST API 요청 방법 # POST 방식으로 작업 실행 # curl 옵션 -X: 전송방식, -H: 헤더정보추가 -d: POST 파라미터(json 형식) # file..
EMR의 마스터 노드에서 실행되는 여러 가지 서비스 중에서 작업 실행 정보를 확인할 수 있는 히스토리 서버 3가지에 대해서 알아보겠습니다. 얀 타임라인 서버 맵리듀스 히스토리 서버 스파크 히스토리 서버 얀 타임라인 서버(YARN Timeline Server) 얀 타임라인 서버는 하둡 클러스터를 통해 작업된 애플리케이션의 기록을 저장하고 조회할 수 있습니다. 실행 중인 애플리케이션, 작업 완료된 애플리케이션의 큐 정보, 사용자 정보, 작업 상태를 확인할 수 있습니다. 사용 방법 curl -s http://$(hostname -f):8188/ws/v1/timeline curl -s http://$(hostname -f):8188/ws/v1/timeline/DS_APP_ATTEMPT curl -s http:/..
EMR 하둡 클러스터에서 사용되는 포트와 기본적인 사용 방법은 다음과 같습니다. 타입 프로세스 포트 사용법 hdfs hdfs 8020 hadoop fs -ls hdfs://$(hostname -f):8020/ webhdfs 50070 curl -s http://$(hostname -f):50070/webhdfs/v1/?op=GETFILESTATUS | jq webhdfs-proxy 14000 curl -s "http:///$(hostname -f):14000/webhdfs/v1?op=GETFILESTATUS&user.name=hadoop" yarn resourcemanager 8032 resourcemanager web UI 8088 lynx http://$(hostname -f):8088 timelin..
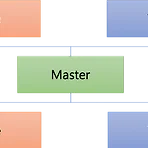 [EMR] EMR의 기본 실행 프로세스 정리
[EMR] EMR의 기본 실행 프로세스 정리
EMR은 마스터 노드, 코어 노드, 태스크 노드로 구성됩니다. 마스터 노드와 코어 노드는 필수입니다. 태스크 노드는 선택사항입니다. 마스터 노드에 EMR 클러스터 운영을 위한 여러 가지 서비스가 실행됩니다. 따라서 마스터 노드의 메모리와 저장공간을 적절하게 설정하는 것이 중요합니다. 코어 노드에는 데이터 노드와 노드 매니저가 실행되고 태스크 노드에는 노드 매니저가 실행됩니다. 마스터 노드 리소스 매니저 실행 EMR 클러스터 관리 네임 노드 실행 HDFS 데이터 노드 관리 그 외 서비스가 실행되어 EMR 클러스터의 관리와 작업을 운영 코어 노드 데이터 노드 실행 HDFS 데이터 저장 노드 매니저 실행 애플리케이션 실행 태스크 노드 노드 매니저 실행 애플리케이션 실행 마스터 노드 실행 프로세스 EMR에서 하..
 [linux][vi] VI 사용 방법
[linux][vi] VI 사용 방법
VI는 터미널 환경에서 많이 사용되는 텍스트 에디터입니다. 리눅스 배포판에 기본적으로 설치되어있고 다양한 기능을 가지고 있어 자주 사용하게 됩니다. 우리가 터미널 환경에서 사용하는 VI는 보통 VIM(Vi Improved)인 경우기 많습니다. VIM은 VI를 개선하여 만들어진 프로그램으로 리눅스에는 기본적으로 VIM이 VI로 alias가 등록되어 있습니다. # vi 명령의 alias 확인 $ alias vi alias vi='vim' VI의 특징 문법 강조 파일 타입을 이용하여 문법 강조 기능 제공 다양한 기능 검색, 치환, 복사, 붙여 넣기, 블록 지정 등 다양한 기본 기능 제공 단축키를 이용하여 빠른 작업 가능 테마 설정 기본 테마 변경 및 사용자 정의 테마 설정 가능 VI 사용 모드 VI는 4가지의..
리눅스의 CLI환경에서 영어를 입력하고 홈(Home) 키나 엔드(End) 키를 이용하여 커서를 이동하려고 할 때 입력한 영어문자가 대문자, 소문자로 변경되는 상태가 될 때가 있습니다. 이는 리눅스 커맨드 라인의 입력 환경이 vi로 설정되어 있어서 발생하는 문제입니다. emacs모드로 변경하면 됩니다. 수정하는 방법은 다음과 같습니다. # set -o 명령으로 변경 # -o는 옵션을 지정하는 명령 $ set -o [vi|emacs] # emacs 모드 변경 $ set -o emacs # vi 모드 변경 $ set -o vi 리눅스는 기본적으로 두 개의 입력환경을 지원합니다. 사용자가 원하는 환경을 개별 사용자의 프로파일(~/.bashrc or ~/.profile)파일이나, OS 전체의 환경 프로파일(/et..
 [빅데이터 아키텍처] 카카오 광고 데이터 처리 서비스
[빅데이터 아키텍처] 카카오 광고 데이터 처리 서비스
카카오 광고 시스템은 하루 59TB의 데이터를 처리하고 있습니다. 데이터 수집 기술 카프카, 로그스태쉬 스파크 스트리밍, 플링크 데이터 처리 하이브, 임팔라 저장 HDFS, 카산드라, HBase, 엘라스틱서치, 레디스 시각화 태블루, 제플린, 카프카, 키린 운영 에어플로우, 그라파나, 키바나, 프로메테우스 카카오는 데이터를 다각도로 분석하기 위해서 키린(Kylin)을 이용하고 있습니다. 키린은 데이터를 큐브 형태로 가공하여 보관하고 있기 때문에 사용자의 쿼리에 빠른 속도로 결과를 제공할 수 있습니다. 작업의 진행상태를 원활하게 확인하기 위해서 에어플로우를 활용하고 있습니다. https://www.slideshare.net/ssuser75ddc6/kylin-olap-on-hadoop 카일린 Kylin, O..
 [빅데이터 아키텍처] 네이버의 빅데이터 플랫폼
[빅데이터 아키텍처] 네이버의 빅데이터 플랫폼
네이버는 HBase와 엘라스틱서치 기반으로 빅데이터 플랫폼을 구성하고 있는 것으로 보입니다. 데이터로그(DataLog) 엘라스틱서치 기반 2017년에 구축한 로그 통합 관리 플랫폼 검색 서비스의 모든 로그를 한곳에 모아 효율적인 분석을 위한 환경을 제공 초당 22만건 실시간 색인이 가능 데이터스토어(DataStore) HBase 기반 데이터 카탈로그를 통해 보관된 데이터의 목록, 상세정보, 생산자와 소비자를 한눈에 알 수 있도록 제공 저장된 데이터의 효율적인 활용을 위해 SQL 기반의 처리 시스템을 구축 비슷한 형태의 요청이 많으므로 SQL 템플릿을 제공하여 처리할 수 있도록 지원(Hue) 빠른 처리를 위해 가공테이블을 제공. 자주 사용되는 데이터를 미리 테이블로 분리하여 적재 하이브의 ORC, 파티션,..
 [빅데이터 아키텍처] 멜론의 빅데이터 플랫폼
[빅데이터 아키텍처] 멜론의 빅데이터 플랫폼
멜론은 초기에는 IBM 네티자 데이터웨어하우스를 도입해 데이터 분석을 처리하였으나, 스케일아웃의 어려움과 비용 부담으로 인하여 오픈 소스를 이용한 빅데이터 플랫폼을 자체 운영하는 것으로 결정하였습니다. 멜론은 마우스의 움직임, 검색, 음악 선택, 클릭 패턴 등 이용자들의 행동을 종합적으로 관찰하고 이를 분석하기 위해 노력하고 있습니다. 멜론의 빅데이터 플랫폼 멜론의 빅데이터 처리 순서는 수집/분석/서비스 단계를 따릅니다. 수집 데이터베이스 데이터 스쿱을 이용하여 수집 로그 데이터 플룸을 이용하여 한시간마다 쉘 스크립트(scp)로 수집 허드슨을 이용하여 배치 데이터를 수집 분석 실시간 분석과 배치 분석을 제공 Hive를 이용하여 분석 결과 제공 데이터의 종류에 따라 MR, Mahout, Tajo, Spar..
하이브 3.0에서 제공하는 구체화 뷰(Materialized Views)에 대해서 알아보겠습니다. 뷰(View)는 논리적인 테이블입니다. 데이터 검색을 위한 구조는 가지고 있지만 실제 데이터는 가지고 있지 않습니다. 구체화 뷰(M-View)는 물리적인 테이블입니다. 구체화 뷰를 생성할 때 데이터를 별도의 저장공간에 저장하여 뷰를 사용할 때 속도를 높일 수 있습니다. 보통 데이터웨어 하우스에서 쿼리의 속도를 높이는데 많이 사용됩니다. 하이브에서 규체화 뷰는 LLAP, Calcite(CBO) 기능과 협력하여 쿼리의 속도를 높이는 데 사용됩니다. 구체화 뷰 생성 구체화 뷰는 생성되는 시점에 테이블의 데이터를 취합하여 데이터를 저장합니다. 이 과정에서 맵리듀스 작업이 발생합니다. 구체화 뷰를 저장하는 기본 서데..
hive udf에서 java.lang.illegalargumentexception argument type mismatch 오류가 발생하는 경우는 파라미터로 전달하는 타입이 설정과 달라서 발생합니다. 아래와 같은 경우 evaluate UDF의 입력값으로 String 이 전달되어야 하는데 다른 타입이 전달되면 오류가 발생합니다. 일반적인 경우에는 타입이 다르다는 것을 알 수 있지만 함수의 중첩으로 처리하는 경우에는 이 오류를 정확하게 확인하기가 어렵습니다. public class SampleUDF extends UDF { public Text evaluate(String text) { // 입력받은 문자를 대문자로 반환 return new Text(text.toUpperCase()); } } 함수의 중첩 ..
Spark SQL을 이용할 때 tez.lib.uris is not defined in the configuration 오류가 발생하는 경우 hive-site.xml파일에 tez 환경 설정을 넣어주면 됩니다. : org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: org.apache.tez.dag.api.TezUncheckedException: Invalid configuration of tez jars, tez.lib.uris is not defined in the configuration; 설정 추가 tez.lib.uris hdfs:///apps/tez/tez.tar.gz tez.use.cluster.hadoop-libs true
EMR 클러스터의 노드에는 클러스터의 인스턴스 개수나 클러스터 ID, 인스턴스 그룹 ID와 같은 정보를 확인하기 위한 json 파일이 있습니다. 이 정보를 확인하면 접속한 EMR의 정보를 알 수 있습니다. . $ cat /mnt/var/lib/info/job-flow.json { "jobFlowId": "j-xxxx", "instanceCount": 50, "masterInstanceId": "i-xxxx", "masterInstanceType": "r2.xlarge", "slaveInstanceType": "r4.2xlarge", "instanceGroups": [ ] }
HDFS는 REST API를 이용하여 파일을 조회하고, 생성, 수정, 삭제하는 기능을 제공합니다. 이 기능을 이용하여 원격지에서 HDFS의 내용에 접근하는 것이 가능합니다. REST API 설정 REST API를 사용하기 위해서는 hdfs-site.xml에 다음의 설정이 되어 있어야 합니다. -- webhdfs 사용여부 설정 dfs.webhdfs.enabled=true; -- webhdfs 포트 설정 dfs.namenode.http-address=0.0.0.0:50070; REST API 사용 방법 위에서 설정한 http 포트로 curl 명령을 이용하여 ls명령을 날리는 예제는 다음과 같습니다. -- /user/hadoop 위치를 조회 $ curl -s http://$(hostname -f):50070/..
 [hive] 벡터화(vectorized) 처리
[hive] 벡터화(vectorized) 처리
하이브 성능 향상의 한 방법인 벡터화(vectorized) 처리는 한 번에 처리하는 데이터의 양을 늘려서 CPU 사용률을 높이고, 처리속도를 빠르게 하는 기법입니다. 검색, 필터, 집계, 조인 처리에서 사용되고, 한 번에 1024개의 행을 동시에 처리하여 속도를 높입니다. 벡터화 설정을 하면 1024행(row)의 블록으로 한번에 작업을 처리합니다. 하나의 블록에서 열(column)은 배열로 처리됩니다. 아래의 클래스와 같이 칼럼이 ColumnVector클래스 배열로 한 번에 읽어서 처리합니다. 조회, 필터링 등에 벡터화를 이용하면 한번에 처리하는 작업이 증가하여 속도가 빨라지게 됩니다. 16억 건의 데이터를 이용해서 count명령을 처리한 결과 벡터화 처리를 하지 않으면 67.6초, 벡터화 처리를 하면 ..
 [hive] 하이브의 조인방식(hive join)
[hive] 하이브의 조인방식(hive join)
하이브의 세가지 조인 방식에 대해서 알아보겠습니다. 셔플조인 매퍼에서 각 테이블을 읽고 셔플 단계에서 조인되는 키를 기준으로 파티션닝후 셔플을 진행하여 각 리듀서에서 조인을 수행 어떤형태의 데이터 크기와 구성에도 사용 가능 가장 자원을 많이 사용하고 느린 조인 방식 맵조인 (브로드캐스트 조인, 맵사이드 조인) 작은 사이즈의 테이블이 메모리에 올라가고, 각 매퍼에서 조인을 수행후 결과를 반환하는 방식 가장 큰 테이블에서 가장 빠른 단일 스캔 작은 테이블은 메모리에 들어갈 정도로 작아야 함 -- 맵조인 사용여부 설정, 3개 이상의 테이블을 조인할 때 맵조인 사용여부 설정하는 옵션 hive> set hive.auto.convert.join=true; hive> set hive.auto.convert.join...
HDFS를 포맷하는 방법에 대해서 알아보겠습니다. HDFS를 포맷하면 데이터가 모두 사라집니다. 반드시 백업을 해두고 진행하는 것이 좋습니다. 작업 순서 작업 순서는 AWS EMR의 HDFS를 기준으로 작성되었습니다. 각 제조사의 하둡마다 순서가 바뀔수 있지만 전체적인 맥락은 변경되지 않습니다. 서버 종료 네임노드, 데이타노드 종료를 종료합니다. 모든 노드의 네임노드 프로세스와 데이타노드 프로세스를 종료합니다. 네임노드 포맷 포맷 hdfs namenode -format 명령으로 네임노드를 포맷합니다. 네임노드를 포맷하면 dfs.namenode.name.dir경로의 fsimage와 edits 파일이 초기화 됩니다. 네임노드를 포맷하면 클러스터 ID가 신규로 생성됩니다. 이 정보는 dfs.namednoe.n..
하이브 2.2.0 버전부터 Blobstore기능을 제공합니다. Blobstore Blobstore는 하이브 작업시에 생성되는 임시 파일을 S3에 작성하지 않고, HDFS에 작성하는 기능을 제공합니다. HDFS가 S3보다 IO속도가 빠르기 때문에 작업의 속도가 빨라지게 됩니다. 해당 기능을 이용하였을 때 1.5배 정도의 속도 증가가 이루어졌습니다. 하이브에서 TEZ로 작업하고 파일 머지까지 발생하는 작업으로 테스트 결과 MR속도와 파일 머지 속도가 빨라서 전체 작업시간이 다음과 같이 HDFS를 사용하는 경우가 1.5배 빠르게 나왔습니다. 하지만 HDFS를 사용하는 경우 임시파일의 저장으로 인한 작업 공간의 사용, 네임노드 관리로 인한 과부하 등의 오버헤드가 발생하기 때문에 작업의 형태에 따라 적절한 선택과..
hadoop fs 명령에서 OutOfMemory 오류가 발생하는 경우가 있습니다. 아래와 같이 디렉토리의 정보를 가져올 때 오류가 발생합니다. $ hadoop fs -ls /app/logs # # java.lang.OutOfMemoryError: GC overhead limit exceeded # -XX:OnOutOfMemoryError="kill -9 %p" # Executing /bin/sh c "kill -9 1234"... KILLED 원인 및 해결방법 주로 파일 개수가 많을 때 발생합니다. 이런 경우 하둡 클라이언트의 메모리를 늘려주면 됩니다. 아래와 같이 입력하여 메모리 설정을 늘려주고 fs 명령을 입력하면 됩니다. export HADOOP_CLIENT_OPTS="-Xmx2048m"
EMR에서 하둡, 하이브 작업시 S3에 동시에 많은 요청이 들어가면 503 Slow Down 오류가 발생합니다. S3의 스펙상으로 동시에 5500개 이상의 요청이 들어가면 오류가 발생합니다. AmazonS3Exception: Internal Error (Service: Amazon S3; Status Code: 500; Error Code: 500 Internal Error; Request ID: A4DBBEXAMPLE2C4D) AmazonS3Exception: Slow Down (Service: Amazon S3; Status Code: 503; Error Code: 503 Slow Down; Request ID: A4DBBEXAMPLE2C4D) https://aws.amazon.com/ko/premi..
 [eclipse] git에서 추가된 브랜치 정보를 가져오지 못할 때 수정 방법
[eclipse] git에서 추가된 브랜치 정보를 가져오지 못할 때 수정 방법
이클립스의 Git 에서 원격지의 브랜치를 불러오지 못할 때 수정하는 방법은 다음과 같습니다. Git 화면으로 이동하고 프로젝트에서 오른버튼 Fetch from Upstream 선택 4. 팝업창에서 Configure 선택 5. Ref Mappings를 수정하기 위해 Modify 선택 6. Remote branch or tag에 * 추가하고 7. Tracking branch에서 * 추가 이렇게 하면 원격지의 브랜치를 가져올 수 있습니다. 매핑에 맞는 브랜치를 지정할 수 있기 때문에 필터링도 할 수 있습니다.
우지에서 워크플로우를 실행할 때 다음의 오류가 발생하는 경우가 있습니다. Because E0701 : E0701: XML schema error, cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration can be found for element 'hive'. 원인 이는 워크플로우 XML이 스키마에 맞게 정상작으로 생성되지 않은 경우에 발생합니다. 우지 버전과 xml의 네임스페이스에 선언한 액션의 버전에 따라 사용할 수 있는 엘리먼트가 정해져 있기 때문에 우지의 버전에 따라 스키마를 잘 선택해야 합니다. 워크플로우에 적용한 스키마 버전과 현재 작성한 XML의 내용을 확인하여 수정해야 합니다.
우지에서 워크플로우를 추가하고 실행하려고 할 때 다음의 오류가 발생하는 경우가 있습니다. Error: E0701:XML schema error, Content is not allowed in prolog. 원인 SAXParser에서 발생하는 이 오류는 보통 XML을 읽지 못하는 경우에 발생합니다. XML을 저장할 때 BOM이 들어가 있는 경우 발생하기도 하지만 우지에서는 workflow의 실행경로를 잘 못 전달하는 경우에 발생할 수 있습니다. 저는 oozie.wf.application.path에 오타가 있어서 워크플로우의 주소가 달라서 이 오류가 발생하였습니다. 해결방법 따라서 path를 입력할 때 경로를 정확하게 입력해야 합니다. hadoop fs -ls 명령으로 해당 경로의 워크플로우를 확인할 수 있..
우지에서 워크플로우를 실행 하려고 할 때 다음과 같은 오류가 발생하는 경우가 있습니다. Error: E0701:XML schema error, Content is not allowed in prolog. 원인 XML 워크플로우를 읽지 못하는 경우 이 오류가 발생합니다. 보통 워크플로우가 형식에 맞지 않거나(XML 파싱 불가, BOM 형식), 오타가 있는 경우에 발생할 수 있습니다. XML 문법을 체크하기 위해서 xmllint 명령을 이용하여 문법오류를 확인해 보는 것이 좋습니다. 저는 워크플로우의 위치를 지정하는 oozie.wf.application.path에 오타가 있어서 워크플로우를 읽을 수 가 없어서 오류가 발생하였습니다. 해결방법 작업 경로를 정확하게 입력하여 주면 됩니다. ls명령으로 해당 경로..
EMR에서 하이브의 테이블에 MSCK 명령을 이용해서 테이블을 재구성할 때 다음의 오류가 발생하는 경우가 있습니다. Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: MSCK is missing partition columns under s3://bucket_name/directory_location 원인 이 오류는 지정한 버켓의 폴더가 없어서 발생하는 오류입니다. S3의 특성상 디렉토리만 생성되면 파일시스템에 따라서 $folder$ 가 생성되면서 이 특수 파일이 옮겨지는 과정에서 누락되면 이 오류가 발생합니다. 해결방법 이 오류는 디렉토리를 만들어서 해결할 수도 있고, 아래의 설정을 이용해서 오류가 있는 폴더는 무시하고 처리할 수 있도록 설정할..
하이브에서 파티션의 정보를 확인할 때 다음의 오류가 발생하는 경우가 있습니다. hive> desc formatted TABLE_NAME partition(partition1='A'); FAILED: Excution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Error in getting fields from serde.Invalid Field null 원인 이 오류는 확인 하려고 하는 파티션의 정보를 부족하게 제공해서 발생합니다. 위의 예제의 경우 partition1과 partition2 두 개의 파티션을 가진 테이블에서 정보를 하나만 제공하여 오류가 발생하였습니다. 해결방법 아래와 같이 테이블의 파티션에 관련된 모..
Spark SQL을 이용할 때 다음의 오류가 발생하는 경우 tez 환경 설정을 넣어주면 됩니다. : org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: org.apache.tez.dag.api.TezUncheckedException: Invalid configuration of tez jars, tez.lib.uris is not defined in the configuration; 설정 tez.lib.uris hdfs:///apps/tez/tez.tar.gz tez.use.cluster.hadoop-libs true
EMR 5.19.0 버전부터 적용된 노드 레이블 설정에 따라서 YARN에 작업을 전달해도 클러스터를 100% 사용하지 못하는 경우가 발생할 수 있습니다. 클러스터의 구성이 CORE 10대 TASK 40대로 구성된 경우 노드레이블은 CORE, DEFAULT 로 구성되며 CORE는 CORE레이블, TASK는 DEFAULT 레이블로 구성됩니다. 이때 AM(Application Master)하나에 컨테이너 하나를 필요로 하는 작업을 실행하면 기본설정(yarn.node-labels.am.default-node-label-expression)에서 CORE 레이블에 AM이 실행되게 설정되어 클러스터의 자원에 여유가 있어도 작업을 실행하지 않고 대기하게 됩니다. 아래와 같이 AM Partition = CORE 인 상태..
MySQL 에서 파일의 데이터를 Load할 때 1290 에러가 발생하는 경우가 있습니다. MySQL 8에서는 로컬의 데이터를 입력할 때 보안상의 이유로 지정한 장소의 파일만 업로드가 가능합니다. 에러코드 Error Code: 1290. The MySQL server is running with the --secure-file-priv option so it cannot execute this statement 샘플 코드 # Load 가능한 폴더 확인 명령 SHOW VARIABLES LIKE 'secure_file_priv'; # 데이터 로드 명령 LOAD DATA INFILE "C:\\ProgramData\\MySQL\\MySQL Server 8.0\\Uploads\\sample.csv" ..
- Total
- Today
- Yesterday
- 오류
- yarn
- Linux
- java
- 파이썬
- 하둡
- AWS
- 정올
- 하이브
- mysql
- airflow
- hbase
- 알고리즘
- Hadoop
- bash
- build
- Tez
- 다이나믹
- nodejs
- SQL
- Python
- ubuntu
- HIVE
- 백준
- error
- oozie
- emr
- S3
- HDFS
- SPARK
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |